Klinik Veriyi Yapay Zekâya Uyumlu Hale Getiren Açık Kaynak Çerçeve: Columbia’dan MEDS Hamlesi
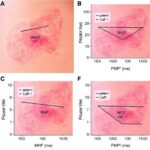
Columbia Üniversitesi’nden araştırmacılar, sağlık verilerinin yapay zekâ çalışmalarında daha düzenli, karşılaştırılabilir ve yeniden kullanılabilir biçimde işlenmesini hedefleyen açık kaynaklı yeni bir çerçeve geliştirdi. MEDS adı verilen sistem, tıbbi veriler için ortak bir yapı sunarak elektronik sağlık kayıtlarının farklı kurumlar arasında daha kolay kullanılmasını amaçlıyor. Araştırmacılara göre bu yaklaşım, klinik yapay zekânın en kronik sorunlarından biri olan veri parçalanmasını azaltabilir ve model geliştirme süreçlerini önemli ölçüde hızlandırabilir.
Medical Extensible Data Standard ifadesinin kısaltması olan MEDS, yalnızca bir veri formatı değil; aynı zamanda birbirleriyle uyumlu hesaplama araçlarından oluşan genişleyebilir bir ekosistem olarak tasarlandı. Bu yapı sayesinde bilim insanları, farklı hastanelerden veya kliniklerden gelen elektronik sağlık kayıtları üzerinde aynı iş akışını daha az uyarlamayla çalıştırabiliyor. Özellikle makine öğrenmesi modellerinin geliştirilmesi, kıyaslanması ve doğrulanması sırasında ortaya çıkan teknik yükün azaltılması, sistemin temel hedefleri arasında yer alıyor.
Sağlık verileri alanında en büyük engellerden biri, klinik bilginin kurumlar arasında ortak bir şemaya göre tutulmaması. Hastaneler çoğu zaman kendi operasyonel gereksinimlerine, kullandıkları yazılım sağlayıcılarına ve yerel veri yönetimi alışkanlıklarına göre farklı kayıt yapıları oluşturuyor. Bu durum, yapay zekâ araştırmacılarının her yeni veri kümesi için baştan sona özel ön işleme boru hatları kurmasını gerektiriyor. Söz konusu süreç hem zaman hem de insan kaynağı açısından maliyetli olduğu için, ölçeklenebilir klinik yapay zekâ uygulamalarının önündeki en güçlü bariyerlerden biri olarak görülüyor.
MEDS’in öne çıkan yönü, bu çeşitliliği tamamen ortadan kaldırmaya çalışmak yerine onun üzerinde ortak bir katman oluşturması. Sistem, kurumlara özgü ayrıntıları soyutlayarak kodun farklı veri ortamlarında daha az değişiklikle çalışmasını hedefliyor. Böylece model geliştirme süreci, tek bir hastane altyapısının teknik sınırlamalarına bağımlı olmaktan çıkabiliyor. Bu da araştırmacıların algoritmayı veri altyapısından kısmen ayırmasına ve aynı yaklaşımı farklı EHR veri kümelerinde daha sistematik biçimde test etmesine olanak tanıyor.
Bu tür bir standardizasyonun bilimsel değeri özellikle yeniden üretilebilirlik açısından önemli. Klinik yapay zekâ çalışmalarında sonuçların başka bir veri kümesinde tekrarlanması çoğu zaman zordur; çünkü analiz kodundan önce verinin hazırlanma biçimi bile kurumdan kuruma değişebilir. MEDS, bu sorunu hafifletmek için standart veri biçimi ile birlikte çalışabilen araçlar sunuyor. Böylece bir çalışmada kullanılan veri işleme mantığının başka bir araştırma ortamında yeniden kurulması daha ulaşılabilir hale geliyor. Bilimsel açıdan bakıldığında bu, yalnızca verimlilik değil, aynı zamanda güvenilirlik meselesi olarak da öne çıkıyor.
Open-source yaklaşımın bir başka sonucu da kurumlar arası iş birliğini kolaylaştırması. Sağlık verileri genellikle hassas ve düzenlemeye tabi olduğu için, araştırma ekipleri farklı sistemlerdeki veriler arasında doğrudan uyum sağlamakta zorlanıyor. Ortak bir teknik standart, her kurumun kendi veri yönetişim kurallarını korurken analiz araçlarını birlikte kullanabilmesini mümkün kılabilir. Columbia ekibinin sunduğu çerçeve, tam da bu noktada, klinik altyapı ile hesaplamalı araştırma arasındaki mesafeyi azaltmayı amaçlıyor.
Uzmanlar, böyle standartların klinik yapay zekâ alanında federated learning gibi veri mahremiyetini gözeten yöntemler için de önem taşıyabileceğini belirtiyor. Çünkü bu tür yaklaşımlarda, verinin tek bir merkezde toplanması yerine farklı kurumlarda kalması gerekir. Ancak veri yapıları uyumsuz olduğunda, dağıtık model eğitimi ve çapraz kurum testleri çok daha karmaşık hale gelir. MEDS’in sağladığı ortak zemin, ileride bu tarz iş birlikçi hesaplama senaryolarının da önünü açabilir.
Bununla birlikte, bu tür çerçevelerin klinik kullanıma doğrudan geçişi zaman alabilir. Sağlık sistemlerinde veri standardizasyonu teknik olduğu kadar yönetsel ve hukuki bir meseledir; dolayısıyla yeni bir açık kaynak aracın benimsenmesi, mevcut iş akışlarının yeniden düzenlenmesini gerektirebilir. Yine de araştırma toplulukları açısından bakıldığında MEDS, dağınık sağlık verisini daha tutarlı bir yapıya oturtmak için dikkat çekici bir adım olarak değerlendiriliyor. Yapay zekâ destekli tıp uygulamalarının olgunlaşması, yalnızca daha güçlü modeller değil, aynı zamanda bu modellerin üzerinde çalıştığı verinin daha anlaşılır ve paylaşılabilir olmasına da bağlı.
Columbia Üniversitesi araştırmacılarının geliştirdiği MEDS, bu ihtiyaca yanıt vermeyi hedefleyen yeni kuşak araçlardan biri olarak öne çıkıyor. Klinik veriyi ortak bir dile çevirmeyi amaçlayan bu yaklaşım, sağlık yapay zekâsının yalnızca daha hızlı değil, aynı zamanda daha tekrarlanabilir ve kurumlar arası daha uyumlu ilerlemesine katkı sağlayabilir.
 Fibrozissiz Engraftman ve Immunosupresyon Gerektirmeyen Hücresel İmplant: Tip 1 Diyabetinde Yeni Ufuklar
Fibrozissiz Engraftman ve Immunosupresyon Gerektirmeyen Hücresel İmplant: Tip 1 Diyabetinde Yeni Ufuklar
 BDE-209’un Bağışıklık Zincirine Uzanan Moleküler Bağ: Ulcerative Kolit ile Olası Bir İlişkinin Hesaplamalı İzleri
BDE-209’un Bağışıklık Zincirine Uzanan Moleküler Bağ: Ulcerative Kolit ile Olası Bir İlişkinin Hesaplamalı İzleri