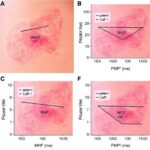
Gerçek Klinik Metinlerde Yapay Zekâyı Ölçmek İçin Yeni Kıstas: BRIDGE
Yapay zekâ destekli büyük dil modelleri, sağlık alanında giderek daha fazla ilgi görüyor; ancak bu sistemlerin gerçek klinik belgeleri ne kadar iyi anladığı sorusu hâlâ tam olarak yanıtlanmış değil. Tıbbi sınav soruları ya da bilimsel veri tabanlarından türetilmiş metinler üzerinde başarılı görünen modeller, çoğu zaman hastane pratiğinin karmaşıklığı karşısında aynı performansı gösteremiyor. Bu boşluğu hedefleyen araştırmacılar, gerçek dünya klinik metinlerinde büyük dil modellerini değerlendirmek için BRIDGE adı verilen kapsamlı bir ölçüm çerçevesi geliştirdi.
BRIDGE, yalnızca tek bir görev ya da tek bir veri kaynağına odaklanmak yerine, farklı hasta bakım basamaklarını temsil eden 87 ayrı klinik görevi bir araya getiriyor. Bu görevler 59 gerçek dünya veri kaynağından derlendi ve dokuz farklı dilde yazılmış metinleri içeriyor. Böylece sistem, hem sağlık verilerinin uluslararası çeşitliliğini hem de klinik dilin farklı bağlamlardaki kullanımını daha gerçekçi biçimde yansıtmayı amaçlıyor. Çerçeve; triyaj, bilgi çıkarımı, tanısal akıl yürütme, prognoz tahmini ile faturalama ve kodlama gibi pratikte kritik rol oynayan aşamaları kapsıyor.
Sağlıkta yapay zekâ değerlendirmesi uzun süredir ölçüt eksikliğiyle karşı karşıya. Mevcut birçok benchmark, sınav tipi sorulara ya da makale özetlerine dayanıyor. Bu tür testler belirli bir düzeyde karşılaştırma sağlasa da, gerçek klinik iş akışlarında karşılaşılan eksik, düzensiz, çok dilli ve bazen de kısaltmalarla dolu metinleri tam olarak temsil etmiyor. Doktor notları, laboratuvar yorumları, epikrizler, sevk yazıları ve idari kayıtlar; bir modelden yalnızca bilgi hatırlamasını değil, aynı zamanda bağlamı yakalamasını, belirsizliği yönetmesini ve uzmanlık alanına özgü ayrıntıları ayırt etmesini bekliyor.
Araştırma ekibine göre BRIDGE’nin temel katkısı da burada yatıyor: modelleri idealize edilmiş bir laboratuvar ortamı yerine, klinik pratiğin dilsel ve yapısal zorluklarıyla yüzleştirmek. Özellikle farklı tıp dallarına yayılan görevler sayesinde, tek bir alanda güçlü görünen bir modelin başka bir uzmanlıkta zorlanıp zorlanmadığı daha net anlaşılabiliyor. Bu yaklaşım, bir modelin yalnızca “tıbbi terimleri tanıması” ile “gerçek klinik iş akışında yararlı olması” arasındaki farkı görünür kılmayı hedefliyor.
Çerçevenin çok dilli yapısı da dikkat çekici. Dokuz dili kapsayan veri seti, klinik yapay zekâ araştırmalarında sıkça göz ardı edilen dil çeşitliliğini merkeze alıyor. Sağlık hizmetlerinin küresel doğası düşünüldüğünde, tek bir dilde performans ölçmek modellerin farklı ülke ve sistemlerde ne kadar uyum sağlayabileceğini anlamak için yetersiz kalabiliyor. BRIDGE, bu nedenle yalnızca İngilizce merkezli değerlendirmelerin ötesine geçerek daha geniş bir klinik gerçekliği temsil etmeye çalışıyor.
Model değerlendirmesinde görevlerin niteliği de en az veri kaynağı kadar önemli. BRIDGE, yalnızca bilgi çıkarma gibi nispeten dar görevleri değil, daha karmaşık klinik muhakeme süreçlerini de içeriyor. Tanı olasılıklarını tartmak, hastalığın gidişatını öngörmek veya idari sınıflandırmaları doğru yapmak, büyük dil modelleri için farklı bilişsel baskılar oluşturuyor. Bu görevlerin aynı çatı altında toplanması, modellerin hangi alanlarda güvenilir, hangi alanlarda kırılgan olduğunu daha ayrıntılı biçimde analiz etmeye imkân veriyor.
Sağlıkta yapay zekânın yükselişi, klinik verinin niteliği üzerine daha derin bir tartışmayı da beraberinde getiriyor. Gerçek dünya metinleri çoğu zaman eksik bilgi içerir, bazen klinik kısaltmalarla yoğunlaşır, bazen de farklı uzmanlıkların terminolojisini aynı belgede birleştirir. Bir modelin bu tür verilerde başarılı olması, yalnızca dil işleme gücünü değil, aynı zamanda klinik bağlamı çözme becerisini de gösterir. Ancak bu performansın ölçülebilmesi için önce ölçüm aracının gerçekçi olması gerekir; BRIDGE tam da bu ihtiyaca yanıt vermek üzere tasarlanmış görünüyor.
Uzmanlar açısından bu tür benchmark’lar, gelecekte klinik karar destek sistemlerinin ne kadar güvenilir olabileceğini anlamada önemli bir ara basamak niteliği taşıyor. Her ne kadar büyük dil modelleri bazı görevlerde etkileyici sonuçlar üretebilse de, sağlık hizmetlerinde kullanım için tutarlılık, izlenebilirlik ve farklı veri türlerine dayanıklılık gerekiyor. BRIDGE gibi kapsamlı kıyaslama setleri, hangi model mimarilerinin klinik metinlerle daha iyi başa çıktığını ve hangi kullanım alanlarında ek doğrulama gerektiğini ortaya koyabilir.
Çalışma, aynı zamanda yapay zekâ araştırmalarında “gerçeklik açığı” olarak tanımlanabilecek bir soruna da işaret ediyor. Bir modelin sınav sorularında iyi performans göstermesi, doğrudan hasta bakımında yararlı olacağı anlamına gelmiyor. Klinik ortamda başarı; dilsel doğruluk kadar görev uygunluğu, bağlam farkındalığı ve güvenilir karar üretimiyle ilişkili. BRIDGE, bu farkı ölçülebilir hale getirmeyi hedefleyerek sağlık alanındaki yapay zekâ araştırmalarına daha sağlam bir değerlendirme zemini sunuyor.
Sonuç olarak BRIDGE, büyük dil modellerinin sağlıkta kullanımını tartışırken ihtiyaç duyulan daha gerçekçi ve çok boyutlu bir test ortamı sağlıyor. Dokuz dil, 59 veri kaynağı ve 87 farklı görevle kurulan bu yapı, klinik metinlerin karmaşıklığını daha iyi yansıtan bir kıyaslama standardı oluşturma yolunda önemli bir adım olarak görülüyor. Yapay zekânın tıpta güvenilir biçimde kullanılabilmesi için, modellerin yalnızca teorik değil, gerçek klinik metinler üzerinde de sınanması gerektiği mesajı bu çalışmayla daha da netleşiyor.
 Kentin Eşiğindeki Tarım Arazilerinde Sınır Yönetimi Kuraklığa Karşı Yeni Bir Kalkan Sunuyor
Kentin Eşiğindeki Tarım Arazilerinde Sınır Yönetimi Kuraklığa Karşı Yeni Bir Kalkan Sunuyor
 Ribozomdan Esinlenen Reaktörler, Zor Peptitlerin Üretiminde Yeni Kapı Açıyor
Ribozomdan Esinlenen Reaktörler, Zor Peptitlerin Üretiminde Yeni Kapı Açıyor
 Dar Alanlarda Göç Eden Nöronlarda Gizli DNA Hasarı Haritası Çıktı
Dar Alanlarda Göç Eden Nöronlarda Gizli DNA Hasarı Haritası Çıktı