Yapay Zekâ, İlaç Sentezinde Darboğazı Açıyor: 50 Binden Fazla Reaksiyonluk Veri Seti C–N Bağlarına Yeni Bakış Getirdi
Yeni ilaçların geliştirilmesi, çoğu zaman laboratuvarlarda yürütülen binlerce ayrı kimyasal denemenin üst üste eklenmesiyle ilerleyen uzun bir süreç. Araştırmacılar, hangi bileşenlerin hangi koşullarda en iyi sonucu verdiğini anlamak için yıllarca sürebilen bir optimizasyon döngüsü içinde çalışıyor. Bu süreç özellikle farmasötik moleküllerin temel iskeletlerinden biri olan karbon-azot (C–N) bağlarının kurulmasında daha da zorlaşıyor. Çünkü bu bağların verimli biçimde oluşturulması, modern ilaç sentezinin en kritik basamaklarından biri kabul ediliyor.
Bu alandaki en yaygın yaklaşımlardan biri, katalizör olarak değerli metallere dayanıyor. Özellikle paladyum, birçok C–N bağlama reaksiyonunda adeta iş gücü niteliğinde kullanılıyor. Ancak bu tercih, bilimsel açıdan etkili olsa da pratikte önemli sorunlar doğuruyor. Paladyum gibi metallerin sınırlı coğrafi dağılımı, yüksek maliyeti ve tedarik zincirlerindeki dalgalanmalar, ilaç geliştirme süreçlerini kırılgan hale getirebiliyor. Buna ek olarak, daha karmaşık hale gelen modern ilaç adayları, sentez kimyasında daha esnek ve sürdürülebilir stratejilere olan ihtiyacı artırıyor.
Bu noktada yapay zekâ, kimya alanındaki en umut verici hızlandırıcı araçlardan biri olarak öne çıkıyor. Makine öğrenimi modelleri, reaksiyon sonucunu tahmin edebilme ve olası sentez yollarını önceden sıralayabilme potansiyeli sayesinde, araştırmacıların deneysel yükünü azaltabilir. Fakat bu yaklaşımın önünde ciddi bir engel var: güvenilir, geniş kapsamlı ve sistematik biçimde oluşturulmuş veri setlerinin eksikliği. Görüntü tanıma ya da doğal dil işleme gibi alanların aksine, kimyasal veriler çoğu zaman parçalı, standart dışı ve eksik biçimde kayıt altına alınıyor. Bu da modellerin genelleme gücünü sınırlıyor.
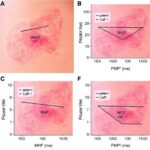
Journal of the American Chemical Society’de yayımlanan yeni çalışma, tam da bu veri sorununun üstüne gidiyor. Araştırmacılar, C–N bağlama kimyası için 50.688 reaksiyonu kapsayan büyük bir veri seti oluşturdu. Çalışma, yalnızca tek tek reaksiyon sonuçlarını listelemekle kalmıyor; aynı zamanda farklı ligandların ve mekanizmalardaki çeşitliliğin daha sistematik biçimde anlaşılmasına da kapı aralıyor. Bilim insanları için bu tür bir kaynak, yalnızca geçmiş deneylerin arşivi değil, gelecekteki deneylerin nasıl tasarlanacağına dair bir yol haritası anlamına geliyor.
Veri setinin önemini artıran unsur, kimyasal reaksiyonların yalnızca “başarılı” ya da “başarısız” olarak sınıflandırılmasının ötesine geçmesi. C–N bağ oluşumunda kullanılan ligandlar, katalizörün davranışını belirleyen temel bileşenlerden biri olarak öne çıkıyor. Çalışma, bazı ligandların farklı koşullarda beklenenden daha geniş bir uyumluluk sergileyebildiğini, bazılarının ise belirli mekanizmalar için daha seçici çalıştığını ortaya koyuyor. Bu tür ayrıntılar, ilaç endüstrisinde laboratuvar denemelerini daha rasyonel hale getirebilir.
Uzmanlara göre burada asıl dönüşüm, verinin sadece miktarında değil, düzeninde yatıyor. Yapay zekâ sistemleri, ham ve düzensiz kimyasal kayıtlarla beslenmek yerine, tutarlı ve karşılaştırılabilir reaksiyon verileriyle eğitildiğinde daha güvenilir tahminler üretebiliyor. Bu durum özellikle yeni moleküllerin sentezinde kritik. Çünkü küçük bir koşul değişikliği, örneğin çözücü seçimi, sıcaklık ya da ligand tipi, reaksiyonun verimini ve seçiciliğini tamamen değiştirebiliyor. Dolayısıyla yüksek kaliteli veri, yalnızca hızlı hesaplama değil, daha akıllı deney tasarımı da sağlıyor.
Paladyuma bağımlılığı azaltmaya yönelik ilgi de bu bağlamda dikkat çekiyor. Araştırma alanı, daha bol bulunan ve daha ucuz metallerin, örneğin nikel ve bakırın, C–N bağ oluşumunda daha etkin kullanılabilmesini hedefleyen yöntemlere uzun süredir yönelmiş durumda. Yeni veri setleri, bu alternatif katalizörlerin hangi koşullarda güçlü performans gösterebileceğini daha iyi anlamaya yardımcı olabilir. Böylece maliyet, tedarik riski ve sürdürülebilirlik açısından daha dengeli sentez stratejileri geliştirilebilir.
Öte yandan, yapay zekâ destekli kimya uygulamalarında beklenti ile gerçeklik arasındaki farkın da göz ardı edilmemesi gerekiyor. Modellerin başarısı, eğitildikleri verinin kalitesine, kapsamına ve çeşitliliğine doğrudan bağlı. Tek bir veri seti, kimyanın tüm karmaşıklığını açıklayamaz. Ancak 50 binden fazla reaksiyonu içeren sistematik çalışmalar, alanın parçalı yapısını bir ölçüde toparlayarak daha sağlam karşılaştırmalar yapılmasına olanak tanıyor. Bu, özellikle düşük verimli ya da zor koşullarda çalışan reaksiyonlar için büyük değer taşıyor.
İlaç keşfi bağlamında bakıldığında, böyle bir altyapı yalnızca sentez basamaklarını kısaltmakla kalmayabilir; aynı zamanda daha uygun maliyetli, daha erişilebilir ve daha ölçeklenebilir üretim yollarının önünü açabilir. Elbette bu tür sonuçlar doğrudan klinik faydaya dönüşmez; yeni ilaç adaylarının güvenlik ve etkinlik süreçleri yine uzun değerlendirmeler gerektirir. Ancak kimyasal sentezde sağlanacak her iyileşme, erken aşama keşif zincirinin tamamını hızlandırma potansiyeli taşır.
Sonuç olarak çalışma, yapay zekânın ilaç kimyasındaki rolünün yalnızca algoritma geliştirmekten ibaret olmadığını hatırlatıyor. Asıl ilerleme, kimyasal bilginin nasıl toplandığı, düzenlendiği ve paylaşılabildiğiyle yakından ilişkili. C–N bağ oluşumuna odaklanan bu büyük veri seti, katalizör seçiminden reaksiyon mekanizması analizine kadar geniş bir alanda daha öngörülebilir bir araştırma ortamı sunabilir. İlaç keşfinin yavaş ama zorunlu temposu içinde, bu tür veri odaklı yaklaşımlar artık yardımcı bir araç değil, temel bir dönüşüm başlığı haline geliyor.
 MS Araştırmasında Yeni Yol: Polimer Mikropartiküller B Hücrelerini Toleransa Yönlendiriyor
MS Araştırmasında Yeni Yol: Polimer Mikropartiküller B Hücrelerini Toleransa Yönlendiriyor
 Akciğer Kanserinde Güven Sorununa Yapay Zekâdan Ölçülebilir Yanıt
Akciğer Kanserinde Güven Sorununa Yapay Zekâdan Ölçülebilir Yanıt
 Dhankuta’nın Yaşlılarında Görünmeyen Hastalık Yükü: Kırsal Bir Vadiden Gelen Sağlık Uyarısı
Dhankuta’nın Yaşlılarında Görünmeyen Hastalık Yükü: Kırsal Bir Vadiden Gelen Sağlık Uyarısı