Çocuk Kardiyolojisinde Yapay Zekâ, Hastanede Kalış Süresini Öngörmede Yeni Bir Eşik Aşıyor
Çocuk kardiyolojisinde tedavi planlaması, yalnızca tanının doğruluğuna değil, aynı zamanda bir hastanın hastanede ne kadar süre kalacağının öngörülebilmesine de bağlı. Nadir görülen doğumsal kalp hastalıklarından sonradan gelişen kardiyak sorunlara kadar uzanan geniş klinik yelpaze, hekimlerin kararlarını çoğu zaman sınırlı veriler ve deneyim temelli değerlendirmelerle şekillendirmesine neden oluyor. Bu tablo, yapay zekâ destekli yeni yöntemlerin önemini artırırken, yayımlanan yeni bir çalışma makine öğrenmesinin çocuk kardiyolojisinde hem yatış süresini tahmin etmede hem de benzer klinik özelliklere sahip hastaları bulmada kullanılabileceğini gösterdi.
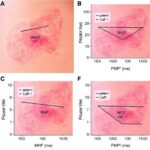
Araştırma, hastanede kalış süresi gibi günlük klinik işleyişi doğrudan etkileyen bir değişkeni daha öngörülebilir hale getirmeyi hedefliyor. Çocuk hastalarda yatış süresinin doğru tahmin edilememesi, kimi zaman gereğinden uzun hastanede kalışa, kimi zamansa erken taburculuğa yol açabiliyor. Her iki senaryo da klinik açıdan risk taşıyor; biri kaynak kullanımını zorlaştırırken diğeri izlem gereksinimi tam karşılanmadan hastanın taburcu edilmesi anlamına gelebiliyor. Yeni çalışma, bu boşluğu veri odaklı bir yaklaşımla azaltmayı amaçlıyor.
Çalışmanın temelinde, makine öğrenmesi algoritmalarının çok boyutlu klinik veriler içinde gizli örüntüleri öğrenebileceği varsayımı yer alıyor. Araştırmacılar, çocuk kardiyoloji hastalarına ait yapılandırılmış ve yapılandırılmamış verileri birlikte değerlendirdi. Bu veri havuzunda demografik bilgiler, tanısal görüntüleme raporları, biyokimyasal belirteçler ve elektronik sağlık kayıtları gibi farklı kaynaklar yer aldı. Klinik pratikte tek başına anlamlı görünmeyen bu değişkenlerin birlikte işlenmesi, modelin hastanın klinik seyrine ilişkin daha bütüncül bir çerçeve kurmasına olanak sağladı.
Veri hazırlama aşaması, çalışmanın en kritik bileşenlerinden biri olarak öne çıktı. Farklı kaynaklardan gelen kayıtların kullanılabilir hale getirilmesi için gürültünün azaltılması, eksik değerlerin tamamlanması ve verilerin normalize edilmesi gibi standartlaştırma adımları uygulandı. Özellikle tıbbi verilerde sık görülen eksik veya düzensiz kayıtlar, makine öğrenmesi modellerinin performansını ciddi biçimde etkileyebildiğinden, bu tür ön işleme süreçleri güvenilir sonuçlar için temel kabul ediliyor. Araştırmada, bu adımların ardından elde edilen birleşik veri seti ileri düzey modellerin eğitimine uygun hale getirildi.
Çalışmanın dikkat çekici yönlerinden biri de yalnızca tahmin yapmakla sınırlı kalmaması. Geliştirilen çerçeve, benzer hasta profillerini geri getirebilen bir hasta benzerliği arama işlevi de içeriyor. Bu özellik, özellikle karmaşık vakalarda klinisyenlerin daha önce benzer tablo göstermiş hastaların seyrini inceleyerek karar desteği almasını mümkün kılabilir. Çocuk kardiyolojisinde aynı tanıya sahip iki hastanın bile tamamen farklı klinik süreçler yaşayabildiği düşünüldüğünde, benzerlik temelli erişim aracı tedavi planlamasını daha kişiselleştirilmiş bir zemine taşıyabilir.